Pääkomponenttien tulkinta. Pääkomponenttimenetelmä (MCM): peruskaavat ja -menettelyt. Tensorien singulaarihajotus ja pääkomponenttien tensorimenetelmä
Tuotanto- ja taloudellisia prosesseja mallinnettaessa mitä alhaisempi tarkastelun kohteena olevan tuotannon osajärjestelmän taso (rakenteellinen puolijako, tutkittava prosessi), sitä tunnusomaisempi syöttöparametreille on ne määräävien tekijöiden suhteellinen riippumattomuus. Analysoitaessa yrityksen tärkeimpiä laadullisia indikaattoreita (työn tuottavuus, tuotekustannukset, voitot ja muut indikaattorit), on käsiteltävä prosessien mallintamista toisiinsa kytketyllä syöttöparametrien (tekijöiden) järjestelmällä. Samaan aikaan järjestelmien tilastollisen mallinnuksen prosessille on ominaista vahva korrelaatio ja joissain tapauksissa lähes lineaarinen riippuvuus määräävistä tekijöistä (prosessin syöttöparametrit). Tässä on kyse multikollineaarisuudesta, ts. syöttöparametrien merkittävä keskinäinen riippuvuus (korrelaatio), regressiomalli ei kuvasta riittävästi tutkittavaa todellista prosessia. Jos lisäät tai hylkäät useita tekijöitä, lisäät tai vähennät alkuinformaation määrää (havaintojen määrää), tämä muuttaa merkittävästi tutkittavan prosessin mallia. Tämän lähestymistavan käyttö voi muuttaa dramaattisesti tutkittavien tekijöiden vaikutusta kuvaavien regressiokertoimien arvoja ja jopa niiden vaikutuksen suuntaa (regressiokertoimien merkki voi muuttua päinvastaiseksi siirtyessä yhdestä mallista toiseen toinen).
Tieteellisen tutkimuksen kokemuksesta tiedetään, että useimmille taloudellisille prosesseille on ominaista parametrien (tutkittavien tekijöiden) suuri keskinäinen vaikutus (vuorovaikutus). Laskettaessa mallinnettujen indikaattoreiden regressiota näille tekijöille syntyy vaikeuksia mallin kertoimien arvojen tulkinnassa. Tällainen malliparametrien multikollineaarisuus on usein luonteeltaan paikallista, eli kaikki tutkittavat tekijät eivät liity merkitsevästi toisiinsa, vaan yksittäiset syöteparametriryhmät. Yleisimmälle multikollineaaristen järjestelmien tapaukselle on ominaista tällainen joukko tutkittuja tekijöitä, joista osa muodostaa erillisiä ryhmiä, joilla on vahvasti toisiinsa liittyvä sisäinen rakenne ja jotka eivät käytännössä liity toisiinsa, ja osa on yksittäisiä tekijöitä, joita ei ole muodostettu lohkoiksi ja jotka liittyvät merkityksettömästi toisiinsa. sekä toisiinsa että muihin ryhmiin kuuluviin tekijöihin, joilla on vahva keskinäinen korrelaatio.
Tämän tyyppisen prosessin mallintamiseksi on tarpeen ratkaista ongelma, kuinka joukko merkittävästi toisiinsa liittyviä tekijöitä korvataan jollain toisella korreloimattomien parametrien joukolla, jolla on yksi tärkeä ominaisuus: uuden riippumattomien parametrien joukon on sisällettävä kaikki tarvittavat tiedot tutkittavan prosessin alkuperäisen tekijäjoukon vaihtelu tai hajonta. Tehokas tapa ratkaista tämä ongelma on käyttää pääkomponenttimenetelmää. Tätä menetelmää käytettäessä syntyy pääkomponenttijoukkojen alkutekijöiden yhdistelmien taloudellisen tulkinnan ongelma. Menetelmän avulla voit vähentää mallin syöttöparametrien määrää, mikä yksinkertaistaa tuloksena olevien regressioyhtälöiden käyttöä.
Pääkomponenttien laskennan ydin on määrittää alkutekijöiden X j korrelaatiomatriisi (kovarianssi) ja löytää matriisin ja vastaavien vektorien tunnusluvut (ominaisuusarvot). Ominaisuusluvut ovat uusien muunnettujen muuttujien varianssit ja kullekin tunnusluvulle vastaava vektori antaa painon, jolla vanhat muuttujat siirtyvät uusiin. Pääkomponentit ovat alkuperäisten tilastosuureiden lineaarisia yhdistelmiä. Siirtyminen alkutekijöistä (havainnoista) pääkomponenttien vektoreihin tapahtuu pyörittämällä koordinaattiakseleita.
Regressioanalyysissä käytetään pääsääntöisesti vain muutamaa ensimmäistä pääkomponenttia, jotka yhteensä selittävät 80-90 % tekijöiden kokonaisalkuvaihtelusta, loput hylätään. Jos kaikki komponentit sisällytetään regressioon, sen tulos alkuperäisten muuttujien kautta ilmaistuna on identtinen moninkertaisen regression yhtälön kanssa.
Algoritmi pääkomponenttien laskemiseen
Sanotaan, että on m vektorit (alkutekijät), joilla on ulottuvuus n(mittojen määrä), jotka muodostavat X-matriisin:
Koska mallinnetun prosessin päätekijöillä on yleensä erilaiset mittayksiköt (toiset ilmaistaan kg, toiset km, toiset rahayksiköissä jne.), vertailla niitä, vertailla vaikutuksen astetta, toimintaa. skaalausta ja keskitystä käytetään. Merkitsemme muunnettuja syöttötekijöitä arvolla y ij. Keskihajonnan (keskineliön) arvot valitaan useimmiten asteikoksi:

missä σ j on X j : n keskihajonta; σj2 - dispersio; - alkutekijöiden keskiarvo annetussa j:nnessä havaintosarjassa
(Keskitetty satunnaismuuttuja on satunnaismuuttujan poikkeama sen matemaattisesta odotuksesta. Arvon x normalisointi tarkoittaa siirtymistä uuteen arvoon y, jonka keskiarvo on nolla ja varianssi yksi).
Määritellään parin korrelaatiokertoimien matriisi
![]()
missä y ij on x j:nnen satunnaismuuttujan normalisoitu ja keskitetty arvo i:nnelle mittaukselle; y ik – k:nnen satunnaismuuttujan arvo.
Arvo r jk kuvaa pisteiden sirontaastetta suhteessa regressioviivaan.
Pääkomponenttien F vaadittu matriisi määritetään seuraavasta suhteesta (tässä käytetään transponoitua, "90 0:lla kierrettyä" suureiden y ij matriisia):

tai käyttämällä vektorimuotoa:

 ,
,
jossa F on pääkomponenttien matriisi, mukaan lukien joukko n saatu arvot m pääkomponentit; matriisin A elementit ovat painokertoimia, jotka määrittävät kunkin pääkomponentin osuuden alkuperäisistä tekijöistä.
Matriisin A elementit löytyvät seuraavasta lausekkeesta
jossa u j on korrelaatiokerroinmatriisin R ominaisvektori; λ j on vastaava ominaisarvo.
Lukua λ kutsutaan kertaluvun m neliömatriisin R ominaisarvoksi (tai ominaisluvuksi), jos on mahdollista valita m-ulotteinen nollasta poikkeava ominaisvektori u siten, että Ru = λu.
Matriisin R kaikkien ominaisarvojen joukko on sama kuin yhtälön |R - λE| kaikkien ratkaisujen joukko. = 0. Jos laajennetaan determinanttia det |R - λE|, saadaan matriisin R ominaispolynomi. Yhtälö |R - λE| = 0 kutsutaan matriisin R ominaisyhtälöksi.

Esimerkki ominaisarvojen ja ominaisvektorien määrittämisestä. Annettu matriisi.
Sen ominaisyhtälö




Tämän yhtälön juuret ovat λ 1 =18, λ 2 =6, λ 3 =3. Etsitään λ 3 vastaava ominaisvektori (suunta). Korvaamalla λ 3 järjestelmään, saamme:
8u 1 – 6u 2 +2u 3 = 0
6u 1 + 7u 2 - 4u 3 = 0
2u 1 - 4u 2 + 3u 3 = 0
Koska tämän järjestelmän determinantti on nolla, voit lineaarisen algebran sääntöjen mukaan hylätä viimeisen yhtälön ja ratkaista tuloksena olevan järjestelmän mielivaltaisen muuttujan suhteen, esimerkiksi u 1 = c = 1
6 u 2 + 2u 3 = - 8c
7 u 2 – 4 u 3 = 6 s
Tästä saamme ominaissuunnan (vektorin) arvolle λ 3 =3
1 samalla tavalla voit löytää ominaisvektorit
Yleinen periaate, joka perustuu pääkomponenttien löytämiseen, on esitetty kuvassa. 29.
 |
Riisi. 29. Kaavio pääkomponenttien liittämisestä muuttujiin
Painotuskertoimet kuvaavat tietyn "piilotetun" yleistävän ominaisuuden (globaalikonseptin) vaikutusastetta (ja suuntaa) mitattujen indikaattoreiden X j arvoihin.
Esimerkki komponenttianalyysin tulosten tulkinnasta:

Pääkomponentin F 1 nimi määräytyy sen rakenteessa olevien merkittävien piirteiden X 1, X 2, X 4, X 6 mukaan, jotka kaikki edustavat tuotantotoiminnan tehokkuuden ominaisuuksia, ts. F 1 - tuotannon tehokkuutta.
Pääkomponentin F2 nimen määrää sen, että sen rakenteessa on merkittäviä ominaisuuksia X3, X5, X7, ts. F2 on tuotantoresurssien koko.
PÄÄTELMÄ
Käsikirja sisältää metodologisia materiaaleja, jotka on tarkoitettu taloudellisen ja matemaattisen mallintamisen hallintaan johtamispäätösten perustelemiseksi. Paljon huomiota kiinnitetään matemaattiseen ohjelmointiin, mukaan lukien kokonaislukuohjelmointi, epälineaarinen ohjelmointi, dynaaminen ohjelmointi, kuljetustyyppiongelmat, jonoteoria ja pääkomponenttimenetelmä. Mallintamista tuotantojärjestelmien organisoinnin ja johtamisen käytännössä sekä liike- ja taloushallinnossa tarkastellaan yksityiskohtaisesti. Esitettävän aineiston tutkimiseen liittyy mallinnus- ja laskentatekniikoiden laajaa käyttöä PRIMA-ohjelmistopaketilla ja Excel-taulukkolaskentaympäristössä.
Pääkomponenttimenetelmä tai komponenttianalyysi(pääkomponenttianalyysi, PCA) on yksi tärkeimmistä menetelmistä eläintieteilijän tai ekologin arsenaalissa. Valitettavasti tapauksissa, joissa on varsin tarkoituksenmukaista käyttää komponenttianalyysiä, käytetään usein klusterianalyysiä.
Tyypillinen tehtävä, johon komponenttianalyysi on hyödyllinen, on tämä: on olemassa tietty joukko objekteja, joista jokaiselle on ominaista tietty (riittävän suuri) määrä ominaisuuksia. Tutkija on kiinnostunut näiden esineiden monimuotoisuudesta heijastuvista kuvioista. Siinä tapauksessa, että on syytä olettaa, että objektit ovat jakautuneet hierarkkisesti alisteisiin ryhmiin, voidaan käyttää klusterianalyysiä - menetelmää luokitukset(jakauma ryhmittäin). Jos ei ole syytä olettaa, että objektien valikoima heijastelee jonkinlaista hierarkiaa, on loogista käyttää vihkiminen(järjestetty järjestely). Jos jokaiselle objektille on tunnusomaista riittävän suuri määrä ominaisuuksia (ainakin useita ominaisuuksia, joita ei voida heijastaa riittävästi yhteen kuvaajaan), on optimaalista aloittaa tietojen tutkiminen pääkomponenttien analyysillä. Tosiasia on, että tämä menetelmä on samalla menetelmä datan ulottuvuuden (ulottuvuuksien lukumäärän) vähentämiseksi.
Jos tarkasteltavana olevalle objektiryhmälle on tunnusomaista yhden ominaisuuden arvot, niiden monimuotoisuuden karakterisointiin voidaan käyttää histogrammia (jatkuville ominaisuuksille) tai pylväskaaviota (diskreetin ominaisuuden taajuuksien karakterisoimiseksi). Jos kohteille on ominaista kaksi ominaisuutta, voidaan käyttää kaksiulotteista sirontadiagrammia, jos kolmea, kolmiulotteista. Entä jos merkkejä on paljon? Voit yrittää heijastaa kaksiulotteisella kuvaajalla objektien suhteellista sijaintia toisiinsa nähden moniulotteisessa avaruudessa. Tyypillisesti tällainen ulottuvuuden väheneminen liittyy tiedon menettämiseen. Eri mahdollisista tällaisten näyttömenetelmien joukosta on valittava se, jossa tiedon menetys on minimaalinen.
Selvitetään, mitä on sanottu yksinkertaisimmalla esimerkillä: siirtyminen kaksiulotteisesta avaruudesta yksiulotteiseen avaruuteen. Kaksiulotteisen avaruuden (tason) määrittävien pisteiden vähimmäismäärä on 3. 9.1.1 näyttää kolmen pisteen sijainnin tasossa. Näiden pisteiden koordinaatit on helppo lukea itse piirustuksesta. Kuinka valita suora viiva, joka kuljettaa mahdollisimman paljon tietoa pisteiden suhteellisista paikoista?
Riisi. 9.1.1. Kolme pistettä kahden ominaisuuden määrittelemällä tasolla. Mille viivalle näiden pisteiden suurin hajonta heijastetaan?
Harkitse pisteiden projektioita viivalla A (näkyy sinisellä). Näiden pisteiden projektioiden koordinaatit suoralle A ovat: 2, 8, 10. Keskiarvo on 6 2 / 3. Varianssi (2-6 2/3)+ (8-6 2/3)+ (10-6 2/3) = 34 2/3.
Harkitse nyt linjaa B (vihreänä). Pistekoordinaatit - 2, 3, 7; keskiarvo on 4, varianssi on 14. Siten pienempi osa varianssista heijastuu riville B kuin riville A.
Mikä tämä osake on? Koska suorat A ja B ovat ortogonaalisia (pystysuoraa), A:lle ja B:lle projisoidun kokonaisvarianssin osuudet eivät leikkaa toisiaan. Tämä tarkoittaa, että meille kiinnostavien kohteiden sijainnin kokonaishajonta voidaan laskea näiden kahden termin summana: 34 2 / 3 +14 = 48 2 / 3. Tässä tapauksessa 71,2 % kokonaisvarianssista projisoidaan riville A ja 28,8 % riville B.
Kuinka voimme määrittää, millä rivillä on suurin varianssiosuus? Tämä suora vastaa kohdepisteiden regressioviivaa, joka on merkitty C:ksi (punainen). Tämä viiva heijastaa 77,2 % kokonaisvarianssista, ja tämä on suurin mahdollinen arvo tietylle pisteiden sijainnille. Sellaista suoraa, jolle projisoidaan maksimiosuus kokonaisvarianssista, kutsutaan ensimmäinen pääkomponentti.
Ja millä rivillä loput 22,8 % kokonaisvarianssista tulee näkyä? Suoralla, joka on kohtisuorassa ensimmäiseen pääkomponenttiin nähden. Tämä suora tulee myös olemaan pääkomponentti, koska siinä heijastuu suurin mahdollinen osuus varianssista (luonnollisesti ottamatta huomioon sitä, mikä heijastui ensimmäiseen pääkomponenttiin). Joten tämä on - toinen pääkomponentti.
Laskettuamme nämä pääkomponentit Statistican avulla (kuvaamme dialogia hieman myöhemmin), saamme kuvan 10. 9.1.2. Pääkomponenttien pisteiden koordinaatit on esitetty standardipoikkeamana.

Riisi. 9.1.2. Kuvassa näkyvän kolmen pisteen sijainti. 9.1.1, kahden pääkomponentin tasolla. Miksi nämä pisteet sijaitsevat suhteessa toisiinsa eri tavalla kuin kuvassa? 9.1.1?
Kuvassa 9.1.2 pisteiden suhteellinen sijainti näyttää muuttuneen. Tällaisten kuvien tulkitsemiseksi oikein tulevaisuudessa on syytä pohtia syitä kuvan 2 pisteiden sijainnin eroihin. 9.1.1 ja 9.1.2 saadaksesi lisätietoja. Piste 1 sijaitsee molemmissa tapauksissa oikealla (sillä on suurempi koordinaatti ensimmäisen piirteen ja ensimmäisen pääkomponentin mukaan) kuin piste 2. Mutta jostain syystä piste 3 alkuperäisessä paikassa on alempana kuin kaksi muuta pistettä ( on piirteen 2 pienin arvo ja kaksi muuta pistettä korkeammalla pääkomponenttien tasolla (sillä on suurempi koordinaatti toista komponenttia pitkin). Tämä johtuu siitä, että pääkomponenttimenetelmä optimoi tarkalleen alkuperäisen datan dispersion valitsemilleen akseleille. Jos pääkomponentti korreloi jonkin alkuperäisen akselin kanssa, komponentti ja akseli voidaan suunnata samaan suuntaan (sillä on positiivinen korrelaatio) tai vastakkaisiin suuntiin (on negatiivinen korrelaatio). Molemmat vaihtoehdot ovat samanarvoisia. Pääkomponenttimenetelmän algoritmi voi "kääntää" mitä tahansa tasoa tai ei; tästä ei kannata vetää johtopäätöksiä.
Kuitenkin kuvan kohdat. 9.1.2 eivät ole yksinkertaisesti "ylösalaisin" verrattuna niiden suhteellisiin asemiin kuvassa 1. 9.1.1; Myös heidän suhteelliset asemansa muuttuivat tietyllä tavalla. Toisen pääkomponentin pisteiden väliset erot näyttävät kasvaneen. Toisen komponentin kokonaisvarianssista 22,76 % "levitti" pisteet samalle etäisyydelle kuin 77,24 % ensimmäisen pääkomponentin aiheuttamasta varianssista.
Jotta pisteiden sijainti pääkomponenttien tasolla vastaisi niiden todellista sijaintia, tämä taso on vääristettävä. Kuvassa 9.1.3. kaksi samankeskistä ympyrää näytetään; niiden säteet liittyvät ensimmäisen ja toisen pääkomponentin heijastamien varianssien osuuksina. Kuvaa vastaava kuva. 9.1.2, on vääristynyt siten, että ensimmäisen pääkomponentin standardipoikkeama vastaa suurempaa ympyrää ja toisen - pienempää ympyrää.

Riisi. 9.1.3. Otimme huomioon, että ensimmäinen pääkomponentti vastaa b O suurempi osuus varianssista kuin toinen. Tätä varten olemme vääristäneet kuvaa. 9.1.2 sovittamalla se kahteen samankeskiseen ympyrään, joiden säteet suhteutetaan pääkomponenteista johtuvien varianssien suhteina. Mutta pisteiden sijainti ei edelleenkään vastaa kuvassa esitettyä alkuperäistä. 9.1.1!
Miksi pisteiden suhteellinen sijainti on kuvassa? 9.1.3 ei vastaa kuvassa olevaa. 9.1.1? Alkuperäisessä kuvassa kuva. 9.1, pisteet sijaitsevat koordinaattiensa mukaisesti, eivät kullekin akselille kohdistettavien varianssiosuuksien mukaan. 1 yksikön etäisyys kuvan 1 ensimmäisen merkin (x-akselia pitkin) mukaan. 9.1.1 pisteiden hajoamista tällä akselilla on pienempi osuus kuin toisen ominaiskäyrän (ordinaatta pitkin) 1 yksikön etäisyys. Ja kuvassa 9.1.1 pisteiden väliset etäisyydet määräytyvät tarkasti niiden yksiköiden mukaan, joilla mitataan ne ominaisuudet, joilla niitä kuvataan.
Monimutkaistaan tehtävää hieman. Taulukossa Kuva 9.1.1 esittää 10 pisteen koordinaatit 10-ulotteisessa avaruudessa. Ensimmäiset kolme pistettä ja kaksi ensimmäistä ulottuvuutta ovat esimerkki, jota juuri tarkastelimme.
Taulukko 9.1.1. Pisteiden koordinaatit lisäanalyysiä varten
|
Koordinaatit |
||||||||||
Koulutustarkoituksiin otamme ensin huomioon vain osan taulukon tiedoista. 9.1.1. Kuvassa 9.1.4 näemme kymmenen pisteen sijainnin kahden ensimmäisen merkin tasolla. Huomaa, että ensimmäinen pääkomponentti (rivi C) meni hieman eri tavalla kuin edellisessä tapauksessa. Ei ihme: sen asemaan vaikuttavat kaikki tarkasteltavat kohdat.

Riisi. 9.1.4. Olemme lisänneet pisteiden määrää. Ensimmäinen pääkomponentti menee hieman eri tavalla, koska siihen vaikuttivat lisätyt pisteet
Kuvassa Kuva 9.1.5 näyttää tarkastelemamme 10 pisteen sijainnin kahden ensimmäisen komponentin tasolla. Huomaa, että kaikki on muuttunut, ei vain kunkin pääkomponentin osuus varianssista, vaan jopa kolmen ensimmäisen pisteen sijainti!

Riisi. 9.1.5. Ordinaatio taulukossa kuvatun 10 pisteen ensimmäisten pääkomponenttien tasossa. 9.1.1. Vain kahden ensimmäisen ominaisuuden arvot otettiin huomioon, taulukon 8 viimeistä saraketta. 9.1.1 ei käytetty
Yleisesti ottaen tämä on luonnollista: koska pääkomponentit sijaitsevat eri tavalla, myös pisteiden suhteellinen sijainti on muuttunut.
Vaikeudet verrata pisteiden sijaintia pääkomponenttitasolla ja niiden ominaisarvojen alkuperäisellä tasolla voivat aiheuttaa sekaannusta: miksi käyttää niin vaikeasti tulkittavaa menetelmää? Vastaus on yksinkertainen. Siinä tapauksessa, että vertailtavia kohteita kuvataan vain kahdella ominaisuudella, on täysin mahdollista käyttää niiden ordinaatiota näiden alkuominaisuuksien mukaan. Kaikki pääkomponenttimenetelmän edut näkyvät moniulotteisen datan tapauksessa. Tässä tapauksessa pääkomponenttimenetelmä osoittautuu tehokkaaksi tapaksi vähentää datan dimensiota.
9.2. Siirtyminen aloitustietoihin, joissa on enemmän ulottuvuuksia
Tarkastellaan monimutkaisempaa tapausta: analysoidaan taulukossa esitettyjä tietoja. 9.1.1 kaikille kymmenelle ominaisuudelle. Kuvassa Kuva 9.2.1 näyttää, kuinka meitä kiinnostavan menetelmän ikkunaa kutsutaan.

Riisi. 9.2.1. Pääkomponenttimenetelmän suorittaminen
Olemme kiinnostuneita vain ominaisuuksien valinnasta analysoitavaksi, vaikka Statistica-dialogi mahdollistaa paljon enemmän hienosäätöä (kuva 9.2.2).

Riisi. 9.2.2. Muuttujien valitseminen analysoitavaksi
Analyysin suorittamisen jälkeen näkyviin tulee ikkuna sen tuloksista, jossa on useita välilehtiä (kuva 9.2.3). Kaikki pääikkunat ovat käytettävissä ensimmäisestä välilehdestä.

Riisi. 9.2.3. Pääkomponenttien analyysitulosten valintaikkunan ensimmäinen välilehti
Voit nähdä, että analyysi tunnisti 9 pääkomponenttia ja käytti niitä kuvaamaan 100 % varianssista, joka näkyy 10 alkuperäisessä ominaisuudessa. Tämä tarkoittaa, että yksi merkki oli tarpeeton, tarpeeton.
Aloitetaan tulosten katselu "Plot case factor voordinates, 2D" -painikkeella: se näyttää pisteiden sijainnin kahden pääkomponentin määrittelemällä tasolla. Napsauttamalla tätä painiketta pääsemme valintaikkunaan, jossa meidän on ilmoitettava, mitä komponentteja käytämme; On luonnollista aloittaa analyysi ensimmäisestä ja toisesta komponentista. Tulos näkyy kuvassa. 9.2.4.

Riisi. 9.2.4. Tarkasteltavana olevien kohteiden suuntaaminen kahden ensimmäisen pääkomponentin tasolle
Pisteiden sijainti on muuttunut, ja tämä on luonnollista: analyysissä on mukana uusia piirteitä. Kuvassa 9.2.4 heijastaa yli 65 % kokonaisdiversiteetistä pisteiden sijainnissa toisiinsa nähden, ja tämä on jo ei-triviaali tulos. Esimerkiksi paluu pöytään. 9.1.1, voit varmistaa, että kohdat 4 ja 7 sekä 8 ja 10 ovat todellakin melko lähellä toisiaan. Niiden väliset erot voivat kuitenkin koskea muita pääkomponentteja, joita kuvassa ei ole esitetty: ne vastaavat loppujen lopuksi myös kolmanneksen jäljellä olevasta vaihtelusta.
Muuten, kun analysoidaan pisteiden sijoittelua pääkomponenttien tasolla, voi olla tarpeen analysoida niiden välisiä etäisyyksiä. Helpoin tapa saada matriisi pisteiden välisistä etäisyyksistä on käyttää klusterianalyysin moduulia.
Miten tunnistetut pääkomponentit liittyvät alkuperäisiin ominaisuuksiin? Tämä selviää napsauttamalla painiketta (Kuva 9.2.3) Plot var. tekijäkoordinaatit, 2D. Tulos näkyy kuvassa. 9.2.5.

Riisi. 9.2.5. Alkuperäisten piirteiden projektiot kahden ensimmäisen pääkomponentin tasoon
Katsomme kahden pääkomponentin tasoa "ylhäältä". Alkupiirteet, jotka eivät liity millään tavalla pääkomponentteihin, ovat kohtisuorassa (tai melkein kohtisuorassa) niihin nähden ja heijastuvat lyhyiksi segmenteiksi, jotka päättyvät lähellä koordinaattien origoa. Näin ollen ominaisuus nro 6 liittyy vähiten kahteen ensimmäiseen pääkomponenttiin (vaikka se osoittaa tietyn positiivisen korrelaation ensimmäisen komponentin kanssa). Segmentit, jotka vastaavat niitä piirteitä, jotka heijastuvat täysin pääkomponenttien tasosta, päättyvät yksikkösäteen ympyrään, joka sulkee sisäänsä kuvan keskipisteen.
Voit esimerkiksi nähdä, että ensimmäiseen pääkomponenttiin vaikuttivat voimakkaimmin ominaisuudet 10 (korreloivat positiivisesti) sekä 7 ja 8 (korreloivat negatiivisesti). Jos haluat tarkastella tällaisten korrelaatioiden rakennetta yksityiskohtaisemmin, voit napsauttaa Muuttujien tekijäkoordinaatit -painiketta ja saada kuvassa 2 näkyvän taulukon. 9.2.6.

Riisi. 9.2.6. Alkuperäisten ominaisuuksien ja tunnistettujen pääkomponenttien (tekijät) väliset korrelaatiot
Ominaisarvot-painike näyttää kutsutut arvot pääkomponenttien ominaisarvot. Kuvassa näkyvän ikkunan yläosassa. 9.2.3, seuraavat arvot näytetään muutamalle ensimmäiselle komponentille; Scree plot -painike näyttää ne helposti luettavassa muodossa (kuva 9.2.7).

Riisi. 9.2.7. Tunnistettujen pääkomponenttien ominaisarvot ja niiden heijastuma osuus kokonaisvarianssista
Ensin sinun on ymmärrettävä, mitä ominaisarvo tarkalleen näyttää. Tämä on pääkomponentissa heijastuvan varianssin mitta, joka mitataan kunkin lähtötiedon ominaisuuden aiheuttaman varianssin määrällä. Jos ensimmäisen pääkomponentin ominaisarvo on 3,4, tämä tarkoittaa, että se vastaa enemmän varianssia kuin alkuperäisen joukon kolme ominaisuutta. Ominaisarvot ovat lineaarisesti suhteessa pääkomponentille kuuluvaan varianssiosuuteen; ainoa asia on, että ominaisarvojen summa on yhtä suuri kuin alkuperäisten piirteiden lukumäärä ja varianssiosuuksien summa on 100% .
Mitä tarkoittaa, että 10 ominaisuuden vaihtelua koskeva tieto heijastui yhdeksään pääkomponenttiin? Se, että yksi alkuperäisistä ominaisuuksista oli tarpeeton, ei lisännyt uutta tietoa. Ja niin se oli; kuvassa 9.2.8 näyttää kuinka taulukossa näkyvä pistejoukko luotiin. 9.1.1.
Pyrkiessään kuvaamaan tutkittavaa aluetta tarkasti analyytikot valitsevat usein suuren määrän riippumattomia muuttujia (p). Tässä tapauksessa voi tapahtua vakava virhe: useat kuvaavat muuttujat voivat luonnehtia riippuvan muuttujan samaa puolta ja sen seurauksena korreloida voimakkaasti keskenään. Riippumattomien muuttujien monikollineaarisuus vääristää vakavasti tutkimuksen tuloksia, joten se tulisi eliminoida.
Pääkomponenttimenetelmällä (yksinkertaistettuna tekijäanalyysimallina, koska tässä menetelmässä ei käytetä yksittäisiä tekijöitä, jotka kuvaavat vain yhtä muuttujaa x i) voit yhdistää voimakkaasti korreloituneiden muuttujien vaikutuksen yhdeksi tekijäksi, joka luonnehtii riippuvaa muuttujaa yhdestä näkökulmasta. Pääkomponenttimenetelmällä tehdyn analyysin tuloksena saavutamme tiedon pakkaamisen vaadittuun kokoon, riippuvan muuttujan m (m) kuvauksen Ensin sinun on päätettävä, kuinka monta tekijää on tunnistettava tässä tutkimuksessa. Pääkomponenttimenetelmän puitteissa ensimmäinen päätekijä kuvaa suurimman prosenttiosuuden riippumattomien muuttujien varianssista, sitten laskevassa järjestyksessä. Siten jokainen myöhempi pääkomponentti, joka tunnistetaan peräkkäin, selittää yhä pienemmän osuuden tekijöiden x i vaihtelusta. Tutkijan tehtävänä on määrittää, milloin vaihtelu muuttuu todella pieneksi ja satunnaiseksi. Toisin sanoen kuinka monta pääkomponenttia on valittava jatkoanalyysiä varten. On olemassa useita menetelmiä tarvittavan tekijöiden määrän rationaaliseen tunnistamiseen. Niistä eniten käytetty on Kaiser-kriteeri. Tämän kriteerin mukaan valitaan vain ne tekijät, joiden ominaisarvot ovat suurempia kuin 1. Näin ollen tekijä, joka ei selitä vähintään yhden muuttujan varianssia vastaavaa varianssia, jätetään pois. Analysoidaan taulukkoa 19, sisäänrakennettu SPSS:ssä: Taulukko 19. Selitetty kokonaisvarianssi Kuten taulukosta 19 voidaan nähdä, tässä tutkimuksessa muuttujat x i korreloivat voimakkaasti keskenään (tämä tunnistettiin myös aiemmin ja näkyy taulukosta 5 "Parilliset korrelaatiokertoimet"), ja siksi ne kuvaavat riippuvaa muuttujaa Y lähes toinen puoli: alun perin ensimmäinen pääkomponentti selittää 90 ,7 % x i:n varianssista, ja vain ensimmäistä pääkomponenttia vastaava ominaisarvo on suurempi kuin 1. Tietenkin tämä on tiedon valinnan haitta, mutta tämä haittapuoli ei ollut ilmeistä itse valintaprosessin aikana. SPSS-analyysin avulla voit valita itsenäisesti pääkomponenttien määrän. Valitaan luku 6 – yhtä suuri kuin riippumattomien muuttujien määrä. Taulukon 19 toisessa sarakkeessa on esitetty pyörimiskuormien neliösummat, joista voidaan päätellä tekijöiden lukumäärästä. Kahta ensimmäistä pääkomponenttia vastaavat ominaisarvot ovat suurempia kuin 1 (55,246 % ja 38,396 %), joten Kaiserin menetelmän mukaan valitaan 2 tärkeintä pääkomponenttia. Toinen tapa tunnistaa tarvittava määrä tekijöitä on tasoituskriteeri. Tämän menetelmän mukaan ominaisarvot esitetään yksinkertaisen graafin muodossa ja kaaviosta valitaan paikka, jossa ominaisarvojen lasku vasemmalta oikealle hidastuu mahdollisimman paljon: Kuva 3. Tason kriteeri Kuten kuvasta 3 voidaan nähdä, ominaisarvojen lasku hidastuu jo toisesta komponentista, mutta jatkuva laskunopeus (erittäin pieni) alkaa vasta kolmannesta komponentista. Siksi kaksi ensimmäistä pääkomponenttia valitaan jatkoanalyysiä varten. Tämä johtopäätös on yhdenmukainen Kaiserin menetelmällä saadun päätelmän kanssa. Siten kaksi ensimmäistä peräkkäin saatua pääkomponenttia valitaan lopulta. Sen jälkeen kun on tunnistettu jatkoanalyysissä käytettävät pääkomponentit, on tarpeen määrittää alkuperäisten muuttujien x i korrelaatio saatujen tekijöiden kanssa ja antaa tämän perusteella komponenteille nimet. Analyysissä käytetään tekijäkuormituksen A matriisia, jonka elementit ovat tekijöiden korrelaatiokertoimet alkuperäisten riippumattomien muuttujien kanssa: Taulukko 20. Kerroinkuormitusmatriisi Tässä tapauksessa korrelaatiokertoimien tulkinta on vaikeaa, joten kahden ensimmäisen pääkomponentin nimeäminen on melko vaikeaa. Siksi käytämme edelleen Varimax-koordinaatiston ortogonaalisen kiertomenetelmän menetelmää, jonka tarkoituksena on kiertää tekijöitä siten, että tulkittavaksi valitaan yksinkertaisin tekijärakenne: Taulukko 21. Tulkintakertoimet Taulukosta 21 voidaan nähdä, että ensimmäinen pääkomponentti liittyy eniten muuttujiin x1, x2, x3; ja toinen - muuttujilla x4, x5, x6. Näin ollen voimme päätellä, että käyttöomaisuuteen tehtyjen investointien määrä alueella (muuttuja Y) riippuu kahdesta tekijästä: - alueen yritysten saamien omien ja lainattujen varojen määrä kaudella (ensimmäinen komponentti, z1); -
sekä alueellisten yritysten rahoitusomaisuusinvestointien intensiteetistä ja ulkomaisen pääoman määrästä alueella (toinen komponentti, z2). Kuva 4. Sirontakaavio Tämä kaavio näyttää pettymystulokset. Heti tutkimuksen alussa yritimme valita datan siten, että tuloksena oleva muuttuja Y jakautui normaalisti, ja melkein onnistuimme. Riippumattomien muuttujien jakautumislait olivat melko kaukana normaalista, mutta yritimme saada ne mahdollisimman lähelle normaalia lakia (valitse tiedot sen mukaan). Kuvasta 4 näkyy, että alkuperäinen hypoteesi riippumattomien muuttujien jakautumislain läheisyydestä normaalilakiin ei vahvistu: pilven muodon tulee olla ellipsin muotoinen, esineiden tulisi sijaita tiheämmin keskellä kuin reunoilla. On syytä huomata, että moniulotteisen otoksen tekeminen, jossa kaikki muuttujat jakautuvat normaalin lain mukaan, on vaikeasti suoritettavissa oleva tehtävä (lisäksi siihen ei aina ole ratkaisua). Tähän päämäärään on kuitenkin pyrittävä: silloin analyysin tulokset ovat tulkittuna merkityksellisempiä ja ymmärrettävämpiä. Valitettavasti meidän tapauksessamme, kun suurin osa työstä on tehty kerätyn datan analysoimiseksi, otoksen muuttaminen on melko vaikeaa. Mutta edelleen, myöhemmissä töissä kannattaa ottaa vakavampi lähestymistapa riippumattomien muuttujien valintaan ja saattaa niiden jakautumisen laki mahdollisimman lähelle normaalia. Pääkomponenttianalyysin viimeinen vaihe on regressioyhtälön rakentaminen pääkomponenteille (tässä tapauksessa ensimmäiselle ja toiselle pääkomponentille). Laskemme SPSS:n avulla regressiomallin parametrit: Taulukko 22. Pääkomponenttien regressioyhtälön parametrit Regressioyhtälö on seuraavanlainen: y = 47 414,184 + 0,916*z1+0,213*z2, (b0) (b1) (b2) Että. b0=47 414,184
näyttää regressioviivan leikkauspisteen tuloksena olevan indikaattorin akselin kanssa; b1 = 0,916 – kertoimen z1 arvon kasvaessa 1:llä käyttöomaisuusinvestoinnin määrän odotettu keskiarvo kasvaa 0,916; b2 = 0,213 – kertoimen z2 arvon kasvaessa yhdellä, käyttöomaisuusinvestoinnin määrän odotettu keskiarvo kasvaa 0,213:lla. Tässä tapauksessa tcr:n arvo ("alpha" = 0,001, "nu" = 53) = 3,46 on pienempi kuin tob kaikille "beta"-kertoimille. Siksi kaikki kertoimet ovat merkittäviä. Taulukko 24. Pääkomponenttien regressiomallin laatu Taulukko 24 heijastaa indikaattoreita, jotka kuvaavat rakennetun mallin laatua, nimittäin: R - moninkertainen korrelaatio - osoittaa, mikä osuus Y:n varianssista selittyy Z:n vaihtelulla; R^2 – determinaatiokerroin – näyttää selitetyn poikkeamien Y osuuden keskiarvostaan. Arvioinnin keskivirhe kuvaa konstruoidun mallin virhettä. Verrataan näitä indikaattoreita tehoregressiomallin vastaaviin indikaattoreihin (sen laatu osoittautui korkeammaksi kuin lineaarisen mallin laatu, joten vertaamme sitä tehomalliin): Taulukko 25. Potenttiregressiomallin laatu Siten moninkertainen k-t-korrelaatio R ja k-t-määritys R^2 tehomallissa ovat hieman korkeammat kuin pääkomponenttimallissa. Lisäksi pääkomponenttimallin standardivirhe on PALJON suurempi kuin tehomallin. Siksi potenssilain regressiomallin laatu on korkeampi kuin pääkomponenteille rakennetun regressiomallin. Varmistetaan pääkomponenttien regressiomalli eli analysoidaan sen merkitys. Tarkastetaan hypoteesi mallin merkityksettömyydestä, lasketaan F(havaittu) = 204,784 (laskettu SPSS:ssä), F(crit) (0,001; 2; 53) = 7,76. F(havaittu)>F(kriitti), siksi hypoteesi mallin merkityksettömyydestä hylätään. Malli on merkittävä. Joten komponenttianalyysin tuloksena havaittiin, että valituista riippumattomista muuttujista x i voidaan erottaa 2 pääkomponenttia - z1 ja z2, ja z1:een vaikuttavat enemmän muuttujat x1, x2, x3 ja z2:een vaikuttavat x4, x5, x6. Pääkomponentteihin perustuva regressioyhtälö osoittautui merkittäväksi, vaikka se onkin laadultaan tehoregressioyhtälöä huonompi. Pääkomponenttien regressioyhtälön mukaan Y on positiivisesti riippuvainen sekä Z1:stä että Z2:sta. Muuttujien xi alkuperäinen multikollineaarisuus ja se, että ne eivät ole jakautuneet normaalijakauman lain mukaan, voivat kuitenkin vääristää konstruoidun mallin tuloksia ja tehdä siitä vähemmän merkitsevän. Ryhmäanalyysi Tämän tutkimuksen seuraava vaihe on klusterianalyysi. Klusterianalyysin tehtävänä on jakaa valitut alueet (n=56) suhteellisen pieneen määrään ryhmiä (klustereita) niiden luonnollisen läheisyyden perusteella suhteessa muuttujien x i arvoihin. Klusterianalyysiä suoritettaessa oletetaan, että kahden tai useamman pisteen geometrinen läheisyys avaruudessa tarkoittaa vastaavien kohteiden fyysistä läheisyyttä, niiden homogeenisuutta (tässä tapauksessa alueiden homogeenisuutta käyttöomaisuusinvestointeihin vaikuttavien indikaattoreiden suhteen). Klusterianalyysin ensimmäisessä vaiheessa on tarpeen määrittää allokoitavien klustereiden optimaalinen määrä. Tätä varten on suoritettava hierarkkinen klusterointi - objektien yhdistäminen peräkkäin klustereiksi, kunnes jäljellä on kaksi suurta klusteria, jotka sulautuvat yhdeksi suurimmalla etäisyydellä toisistaan. Hierarkkisen analyysin tulos (päätelmä optimaalisesta klusterimäärästä) riippuu klustereiden välisen etäisyyden laskentamenetelmästä. Siksi testaamme erilaisia menetelmiä ja teemme asianmukaiset johtopäätökset. Lähin naapuri menetelmä Jos laskemme yksittäisten kohteiden välisen etäisyyden yhdellä tavalla - yksinkertaisena euklidisena etäisyydenä - klusterien välinen etäisyys lasketaan eri menetelmillä. Lähimmän naapurin menetelmän mukaan klusterien välinen etäisyys vastaa kahden eri klusterin kohteen välistä minimietäisyyttä. Analyysi SPSS:ssä etenee seuraavasti. Ensin lasketaan etäisyysmatriisi kaikkien kohteiden välillä, ja sitten etäisyysmatriisin perusteella objektit yhdistetään peräkkäin klustereiksi (jokaiselle vaiheelle matriisi käännetään uudelleen). Jaksottaisen liitoksen vaiheet on esitetty taulukossa: Taulukko 26. Agglomeroitumisen vaiheet. Lähin naapuri menetelmä Kuten taulukosta 26 voidaan nähdä, ensimmäisessä vaiheessa elementit 7 ja 8 yhdistettiin, koska niiden välinen etäisyys oli minimaalinen - 0,003. Lisäksi yhdistettyjen kohteiden välinen etäisyys kasvaa. Taulukosta voit myös päätellä optimaalisen klustereiden lukumäärän. Tätä varten sinun on katsottava, mikä askel on jyrkkä hyppy etäisyydellä, ja vähennettävä tämän taajaman lukumäärä tutkittavien kohteiden määrästä. Meidän tapauksessamme: (56-53)=3 on optimaalinen klusterien lukumäärä. Kuva 5. Dendrogrammi. Lähin naapuri menetelmä Samanlainen johtopäätös klustereiden optimaalisesta määrästä voidaan tehdä katsomalla dendrogrammia (kuva 5): 3 klusteria tulisi tunnistaa, ja ensimmäinen klusteri sisältää objektit numeroilla 1-54 (yhteensä 54 objektia) ja toinen klusteri. ja kolmannet klusterit sisältävät kukin yhden objektin (numerot 55 ja 56). Tämä tulos viittaa siihen, että ensimmäiset 54 aluetta ovat suhteellisen homogeenisia käyttöomaisuusinvestointeihin vaikuttavien indikaattoreiden suhteen, kun taas kohteet numeroilla 55 (Dagestanin tasavalta) ja 56 (Novosibirskin alue) erottuvat merkittävästi yleisestä taustasta. On syytä huomata, että näillä aiheilla on suurimmat käyttöomaisuusinvestoinnit valituista alueista. Tämä tosiasia osoittaa jälleen kerran tuloksena olevan muuttujan (investointivolyymin) suuren riippuvuuden valituista riippumattomista muuttujista. Samanlainen päättely tehdään muille klustereiden välisen etäisyyden laskentamenetelmille. "Kaukainen naapuri" -menetelmä Taulukko 27. Agglomeraatiovaiheet. "Kaukainen naapuri" -menetelmä Kaukaisen naapurin menetelmässä klusterien välinen etäisyys lasketaan kahden objektin välisenä maksimietäisyydenä kahdessa eri klusterissa. Taulukon 27 mukaan optimaalinen klusterimäärä on (56-53)=3. Kuva 6. Dendrogrammi. "Kaukainen naapuri" -menetelmä Dendrogrammin mukaan optimaalinen ratkaisu olisi myös allokoida 3 klusteria: ensimmäinen klusteri sisältää alueita numeroilla 1-50 (50 aluetta), toinen - numeroitu 51-55 (5 aluetta) ja kolmas - viimeinen alue. numerolla 56. Painopisteen menetelmä "Painopiste"-menetelmällä klusterien väliseksi etäisyydeksi otetaan klusterien "painokeskipisteiden" välinen euklidinen etäisyys - niiden indikaattoreiden aritmeettinen keskiarvo x i. Kuva 7. Dendrogrammi. Painopisteen menetelmä Kuva 7 osoittaa, että optimaalinen klusterien lukumäärä on seuraava: 1 klusteri – 1-47 objektia; klusteri 2 – 48-54 kohdetta (yhteensä 6); Ryhmä 3 – 55 kohdetta; Ryhmä 4 – 56 kohdetta. "keskiyhteyden" periaate Tässä tapauksessa klusterien välinen etäisyys on yhtä suuri kuin kaikkien mahdollisten havaintoparien välisten etäisyyksien keskiarvo, kun yksi havainto on otettu yhdestä klusterista ja toinen vastaavasti toisesta. Agglomeraatiovaiheiden taulukon analyysi osoitti, että optimaalinen klusterien lukumäärä on (56-52)=4. Verrataan tätä johtopäätöstä dendrogrammianalyysistä saatuun johtopäätökseen. Kuvassa 8 näkyy, että klusteri 1 sisältää objektit numeroilla 1-50, klusteri 2 - objektit 51-54 (4 objektia), klusteri 3 - alue 55, klusteri 4 - alue 56. Kuva 8. Dendrogrammi. "Keskimääräinen yhteys" -menetelmä Analyysin lähtökohtana on datamatriisi mitat elementtien kanssa Parin korrelaatiokertoimien matriisi lasketaan: Yksikköelementit sijaitsevat matriisin päädiagonaalissa Komponenttianalyysimalli on rakennettu esittämällä alkuperäinen normalisoitu data pääkomponenttien lineaarisena yhdistelmänä: Missä Matriisimuodossa mallilla on muoto Tässä Matriisi Elementti Korrelaatiomatriisi Yksiköt sijaitsevat korrelaatiomatriisin päädiagonaalia pitkin ja vastaavasti kovarianssimatriisin kanssa, ne edustavat käytetyn matriisin varianssia. Korrelaatiomatriisi voidaan muuntaa diagonaalimatriisiksi, eli matriisiksi, jonka kaikki arvot diagonaalisia lukuun ottamatta ovat nolla: Missä Ominaisarvot Omavektori Normalisoitu ominaisvektori Ei-diagonaalisten termien katoaminen tarkoittaa, että piirteet tulevat itsenäisiksi toisistaan ( Koko järjestelmän kokonaisvarianssi Pääkomponenttimenetelmässä korrelaatiomatriisi lasketaan ensin alkuperäisestä tiedosta. Sitten se muunnetaan ortogonaalisesti ja sitä kautta löydetään tekijäkuormitukset Tekijänkuormamatriisi A voidaan määritellä seuraavasti Tekijöiden paino Tekijäkuormitukset vaihtelevat -1:stä +1:een ja ovat analogisia korrelaatiokertoimien kanssa. Tekijäkuormitusmatriisissa on välttämätöntä tunnistaa merkittävät ja merkityksettömät kuormitukset Studentin t-testillä Kuormien neliösumma Kaikkien tekijöiden kuormitusten neliöiden summa riville on yhtä suuri kuin yksi, yhden muuttujan kokonaisvarianssi ja kaikkien muuttujien kaikkien tekijöiden summa on yhtä suuri kuin kokonaisvarianssi (eli korrelaatiomatriisin jälki tai järjestys, tai sen ominaisarvojen summa) Yleensä i:nnen attribuutin tekijärakenne esitetään muodossa Missä Tekijälatausten matriisia käyttämällä korrelaatiomatriisi voidaan rekonstruoida: Pääkomponenttien selittämää osaa muuttujan varianssista kutsutaan yhteisöllisyydeksi Missä Erityinen panos Tilin kokonaispanos Käytetään yleensä analyysiin Tekijälatausmatriisia A käytetään pääkomponenttien tulkitsemiseen, tyypillisesti huomioiden ne arvot, jotka ovat suurempia kuin 0,5. Pääkomponenttien arvot määritellään matriisin avulla Pääkomponenttimenetelmä(PCA – pääkomponenttianalyysi) on yksi tärkeimmistä tavoista pienentää datan ulottuvuutta minimaalisella tiedonhäviöllä. Karl Pearsonin vuonna 1901 keksimä se on laajalti käytössä monilla aloilla. Esimerkiksi tiedon pakkaamiseen, "tietokonenäköön", näkyvän kuvan tunnistukseen jne. Pääkomponenttien laskenta rajoittuu alkuperäisen datan kovarianssimatriisin ominaisvektorien ja ominaisarvojen laskemiseen. Pääkomponenttimenetelmää kutsutaan usein Karhunen-Löwe-muunnos(Karhunen-Loeve muunnos) tai Hotellitoiminnan muutos(Hotellitoiminnan muutos). Myös matemaatikot Kosambi (1943), Pugachev (1953) ja Obukhova (1954) työskentelivät tämän asian parissa. Pääkomponenttianalyysin tehtävänä on likimääräinen (lähentää) dataa pienemmän ulottuvuuden lineaarisilla monistimella; etsi ortogonaalisesta projektiosta pienempiä aliavaruuksia, joissa datan leviäminen (eli keskihajonnan keskiarvosta) on suurin; Etsi ortogonaalisesta projektiosta pienemmän ulottuvuuden aliavaruuksia, joissa pisteiden välinen keskiarvoetäisyys on suurin. Tässä tapauksessa ne toimivat äärellisillä datasarjoilla. Ne ovat vastaavia eivätkä käytä hypoteeseja tietojen tilastollisesta muodostamisesta. Lisäksi pääkomponenttianalyysin tehtävänä voi olla konstruoida annetulle moniulotteiselle satunnaismuuttujalle sellainen ortogonaalinen koordinaattimuunnos, jonka seurauksena yksittäisten koordinaattien väliset korrelaatiot tulevat nollaksi. Tämä versio toimii satunnaismuuttujilla. Kuva 3 Yllä olevassa kuvassa on pisteet P i tasossa, p i on etäisyys P i:stä suoraan AB. Etsimme suoraa AB, joka minimoi summan Pääkomponenttimenetelmä alkoi rajallisen pistejoukon parhaan approksimoinnin (approksimoinnin) ongelmalla suorilla ja tasoilla. Esimerkiksi, jos annetaan äärellinen joukko vektoreita. Jokaiselle k = 0,1,...,n? 1 kaikkien k-ulotteisten lineaaristen monistojen joukossa siten, että neliöityjen poikkeamien x i summa L k:stä on minimaalinen: Missä? Euklidinen etäisyys pisteestä lineaariseen monistoputkeen. Mikä tahansa k-ulotteinen lineaarinen jakosarja in voidaan määritellä joukoksi lineaarisia yhdistelmiä, joissa i:n parametrit kulkevat todellista linjaa pitkin, vai mitä? ortonormaali vektoreiden joukko missä on euklidinen normi? Euklidinen pistetulo tai koordinaattimuodossa: Approksimaatiotehtävän ratkaisu k = 0,1,...,n? 1 on annettu joukko sisäkkäisiä lineaarisia jakoputkia Nämä lineaariset monisarjat määritellään ortonormaalilla vektoreiden joukolla (pääkomponenttivektorit) ja vektorilla a . Vektoria a 0 etsitään ratkaisuna L 0:n minimointiongelmaan: Tuloksena on näytekeskiarvo: Ranskalainen matemaatikko Maurice Fréchet Fréchet Maurice René (09/02/1878 - 06/04/1973) - erinomainen ranskalainen matemaatikko. Hän työskenteli topologian ja funktionaalisen analyysin sekä todennäköisyysteorian alalla. Nykyaikaisten metrisen tilan, tiiviyden ja täydellisyyden käsitteiden kirjoittaja. Auto. vuonna 1948 hän huomasi, että keskiarvon variaatiomäärittely pisteenä, joka minimoi datapisteiden neliöetäisyyksien summan, on erittäin kätevä tilastojen muodostamiseen mielivaltaisessa metriavaruudessa, ja hän rakensi klassisten tilastojen yleistyksen yleisavaruuksille. , jota kutsutaan yleistetyksi pienimmän neliösumman menetelmäksi. Pääkomponenttien vektorit löytyvät ratkaisuna vastaaviin optimointiongelmiin: 1) keskitä tiedot (vähennä keskiarvo): 2) löytää ensimmäinen pääkomponentti ratkaisuksi ongelmaan; 3) Vähennä datasta projektio ensimmäiseen pääkomponenttiin: 4) löytää toinen pääkomponentti ratkaisuksi ongelmaan Jos ratkaisu ei ole ainutlaatuinen, valitse yksi niistä. 2k-1) Vähennä projektio (k ? 1):nnelle pääkomponentille (muista, että projektiot edelliseen (k ? 2) pääkomponenttiin on jo vähennetty): 2k) Etsi k:s pääkomponentti ratkaisuksi ongelmaan: Jos ratkaisu ei ole ainutlaatuinen, valitse yksi niistä. Riisi. 4 Ensimmäinen pääkomponentti maksimoi dataprojektion otosvarianssin. Oletetaan esimerkiksi keskitetty joukko datavektoreita, joissa aritmeettinen keskiarvo x i on nolla. Tehtävä? etsi ortogonaalinen muunnos uuteen koordinaattijärjestelmään, jolle seuraavat ehdot olisivat tosia: 1. Datan otosvarianssi ensimmäistä koordinaattia (pääkomponenttia) pitkin on maksimi; 2. Datan näytedispersio pitkin toista koordinaattia (toinen pääkomponentti) on suurin ehdolla, että se on ortogonaalisesti ensimmäiseen koordinaattiin nähden; 3. Datan näytedispersio k:nnen koordinaatin arvoja pitkin on suurin ehdolla ortogonaalisuus ensimmäiseen k? 1 koordinaatit; Datan näytevarianssi normalisoidun vektorin a k määrittelemässä suunnassa on (koska data on keskitetty, otosvarianssi tässä on sama kuin nollasta poikkeaman keskineliö). Parhaiten sopivan ongelman ratkaiseminen antaa samat pääkomponentit kuin suurimman sironnan omaavien ortogonaalisten projektioiden löytäminen, erittäin yksinkertaisesta syystä: ja ensimmäinen termi ei riipu k:stä. Tietojen muunnosmatriisi pääkomponenteille muodostetaan pääkomponenttien vektoreista "A": Tässä a i ovat ortonormaalit sarakevektorit pääkomponenteista, jotka on järjestetty ominaisarvojen laskevaan järjestykseen, yläindeksi T tarkoittaa transponointia. Matriisi A on ortogonaalinen: AA T = 1. Muunnoksen jälkeen suurin osa datan vaihtelusta keskittyy ensimmäisiin koordinaatteihin, mikä mahdollistaa loput hylkäämisen ja supistetun avaruuden huomioimisen. Vanhin menetelmä pääkomponenttien valintaan on Kaiserin sääntö, Kaiser Johann Henrich Gustav (16.3.1853, Brezno, Preussia - 14.10.1940, Saksa) - erinomainen saksalainen matemaatikko, fyysikko, spektrianalyysin alan tutkija. Auto. jonka mukaan ne pääkomponentit, joille ovat merkittäviä eli l i ylittää keskiarvon l (datavektorin koordinaattien keskimääräinen näytevarianssi). Kaiserin sääntö toimii hyvin yksinkertaisissa tapauksissa, joissa on useita pääkomponentteja, joiden l i on paljon suurempi kuin keskiarvo, ja loput ominaisarvot ovat sitä pienempiä. Monimutkaisemmissa tapauksissa se voi tuottaa liian monta merkittävää pääkomponenttia. Jos data normalisoidaan yksikkönäytevarianssiksi akseleita pitkin, niin Kaiserin sääntö saa erityisen yksinkertaisen muodon: vain ne pääkomponentit, joille l i > 1 ovat merkitseviä. Yksi suosituimmista heuristisista lähestymistavoista vaadittujen pääkomponenttien määrän arvioimiseksi on rikki kepin sääntö, kun yksikkösummaan (, i = 1,...n) normalisoitua ominaisarvojen joukkoa verrataan yksikköpituisen kepin fragmenttien pituusjakaumaan, joka on katkennut kohdassa n? Ensimmäinen satunnaisesti valittu piste (katkopisteet valitaan itsenäisesti ja jakautuvat tasaisesti kepin pituudelle). Jos L i (i = 1,...n) ovat tuloksena olevien kepin kappaleiden pituudet, jotka on numeroitu laskevassa pituusjärjestyksessä: , niin L i:n matemaattinen odotus: Katsotaanpa esimerkkiä, joka sisältää pääkomponenttien määrän arvioinnin käyttämällä rikkoutuneen kepin sääntöä ulottuvuudessa 5. Riisi. 5. Rikkoutuneen kepin säännön mukaan k:s ominaisvektori (ominaarvojen l i laskevassa järjestyksessä) tallennetaan pääkomponenttien luetteloon, jos Yllä olevassa kuvassa on esimerkki 5-ulotteisesta tapauksesta: l 1 =(1+1/2+1/3+1/4+1/5)/5; l2 =(1/2+1/3+1/4+1/5)/5; 13 =(1/3+1/4+1/5)/5; 14 =(1/4+1/5)/5; l 5 = (1/5)/5. Esimerkiksi valittu 0.5; =0.3; =0.1; =0.06; =0.04. Rikkinäisen kepin säännön mukaan tässä esimerkissä sinun tulee jättää 2 pääkomponenttia: Yksi asia, joka on pidettävä mielessä, on, että rikkinäinen keppisääntö yleensä aliarvioi merkittävien pääkomponenttien lukumäärän. Ensimmäiselle k pääkomponentille c projisoinnin jälkeen on kätevää normalisoida yksikkö(otos)varianssi akseleilla. Dispersio i:nnettä pääkomponenttia pitkin on yhtä suuri kuin), joten normalisointia varten on tarpeen jakaa vastaava koordinaatti arvolla. Tämä muunnos ei ole ortogonaalinen eikä säilytä pistetuloa. Dataprojektion kovarianssimatriisista normalisoinnin jälkeen tulee yksikkö, projektioista mihin tahansa kahteen ortogonaaliseen suuntaan tulee itsenäisiä suureita ja mistä tahansa ortonormaalista kannasta tulee pääkomponenttien perusta (muista, että normalisointi muuttaa vektorien ortogonaalisuussuhdetta). Matriisi määrittää lähdetietoavaruuden kartoituksen ensimmäiseen k pääkomponenttiin normalisoinnin kanssa Juuri tätä transformaatiota kutsutaan useimmiten Karhunen-Loeve-muunnokseksi eli itse pääkomponenttimenetelmäksi. Tässä a i ovat sarakevektoreita ja yläindeksi T tarkoittaa transponointia. Tilastoissa pääkomponenttimenetelmää käytettäessä käytetään useita erikoistermejä. Data Matrix, jossa jokainen rivi on esikäsitellyn tiedon vektori (keskitetty ja oikein normalisoitu), rivien lukumäärä on m (tietovektoreiden määrä), sarakkeiden määrä on n (tietoavaruuden ulottuvuus); Lataa matriisi(Lataukset), jossa jokainen sarake on pääkomponenttivektori, rivien lukumäärä on n (tietoavaruuden ulottuvuus), sarakkeiden lukumäärä on k (projektioon valittujen pääkomponenttivektorien määrä); Tilimatriisi(Pisteet) jossa jokainen suora on datavektorin projektio k pääkomponentille; rivien lukumäärä - m (tietovektorien lukumäärä), sarakkeiden lukumäärä - k (projektioon valittujen pääkomponenttivektorien lukumäärä); Z-pistematriisi(Z-pisteet) jossa kukin rivi on datavektorin projektio k pääkomponenttiin normalisoituna yksikkönäytevarianssiin; rivien lukumäärä - m (tietovektorien lukumäärä), sarakkeiden lukumäärä - k (projektioon valittujen pääkomponenttivektorien lukumäärä); Virhe Matrix (jäämiä) (Virheet tai jäännökset) Peruskaava: Näin ollen pääkomponenttimenetelmä on yksi matemaattisten tilastojen päämenetelmistä. Sen päätarkoituksena on erottaa aineistojen tutkimisen tarve ja niiden käyttö mahdollisimman vähän.
Komponentti Alkuperäiset ominaisarvot Pyörimiskuormien neliöiden summat
Kaikki yhteensä % Varianssi kumulatiivinen % Kaikki yhteensä % Varianssi kumulatiivinen %
ulottuvuus0
5,442
90,700
90,700
3,315
55,246
55,246
,457
7,616
98,316
2,304
38,396
93,641
,082
1,372
99,688
,360
6,005
99,646
,009
,153
99,841
,011
,176
99,823
,007
,115
99,956
,006
,107
99,930
,003
,044
100,000
,004
,070
100,000
Uuttomenetelmä: Pääkomponenttianalyysi.
Komponenttimatriisi a
Komponentti
X1 ,956
-,273
,084
,037
-,049
,015
X2 ,986
-,138
,035
-,080
,006
,013
X3 ,963
-,260
,034
,031
,060
-,010
X4 ,977
,203
,052
-,009
-,023
-,040
X5 ,966
,016
-,258
,008
-,008
,002
X6 ,861
,504
,060
,018
,016
,023
Uuttomenetelmä: Pääkomponenttianalyysi.
a. Uutetut komponentit: 6
Kierrettyjen komponenttien matriisi a
Komponentti
X1 ,911
,384
,137
-,021
,055
,015
X2 ,841
,498
,190
,097
,000
,007
X3 ,900
,390
,183
-,016
-,058
-,002
X4 ,622
,761
,174
,022
,009
,060
X5 ,678
,564
,472
,007
,001
,005
X6 ,348
,927
,139
,001
-,004
-,016
Uuttomenetelmä: Pääkomponenttianalyysi. Kiertomenetelmä: Varimax Kaiser-normalisoinnilla.
a. Kierto konvergoi 4 iteraatiossa.

Malli Standardoimattomat kertoimet Standardoidut kertoimet t Arvo
B Std. Virhe Beeta
(Vakio) 47414,184
1354,505
35,005
,001
Z1 26940,937
1366,763
,916
19,711
,001
Z2 6267,159
1366,763
,213
4,585
,001
Malli R R-neliö Säädetty R-neliö Std. arviovirhe
ulottuvuus0
.941 a ,885
,881
10136,18468
a. Ennustajat: (jatkuva) Z1, Z2
b. Riippuva muuttuja: Y
Vaihe Klusteri on yhdistetty Kertoimet Seuraava vaihe
Klusteri 1 Klusteri 2 Klusteri 1 Klusteri 2
,003
,004
,004
,005
,005
,005
,005
,006
,007
,007
,009
,010
,010
,010
,010
,011
,012
,012
,012
,012
,012
,013
,014
,014
,014
,014
,015
,015
,016
,017
,018
,018
,019
,019
,020
,021
,021
,022
,024
,025
,027
,030
,033
,034
,042
,052
,074
,101
,103
,126
,163
,198
,208
,583
1,072

Vaihe Klusteri on yhdistetty Kertoimet Klusterin ensimmäisen ilmestymisen vaihe Seuraava vaihe
Klusteri 1 Klusteri 2 Klusteri 1 Klusteri 2
,003
,004
,004
,005
,005
,005
,005
,007
,009
,010
,010
,011
,011
,012
,012
,014
,014
,014
,017
,017
,018
,018
,019
,021
,022
,026
,026
,027
,034
,035
,035
,037
,037
,042
,044
,046
,063
,077
,082
,101
,105
,117
,126
,134
,142
,187
,265
,269
,275
,439
,504
,794
,902
1,673
2,449


 , jonka i:s rivi kuvaa i:ttä havaintoa (objektia) kaikille k indikaattorille
, jonka i:s rivi kuvaa i:ttä havaintoa (objektia) kaikille k indikaattorille  . Lähdetiedot normalisoidaan, jolle lasketaan indikaattoreiden keskiarvot
. Lähdetiedot normalisoidaan, jolle lasketaan indikaattoreiden keskiarvot  , sekä keskihajonnan arvot
, sekä keskihajonnan arvot  . Sitten normalisoitujen arvojen matriisi
. Sitten normalisoitujen arvojen matriisi


 .
.
 - "paino", ts. tekijälataus
- "paino", ts. tekijälataus  pääkomponentti päällä
pääkomponentti päällä  -th muuttuja;
-th muuttuja; -merkitys
-merkitys  th pääkomponentti
th pääkomponentti  -havainto (objekti), missä
-havainto (objekti), missä  .
.
 - ulottuvuuden pääkomponenttien matriisi
- ulottuvuuden pääkomponenttien matriisi  ,
, - samanmittaisten tekijäkuormien matriisi.
- samanmittaisten tekijäkuormien matriisi. kuvailee
kuvailee  havaintoja avaruudessa
havaintoja avaruudessa  pääkomponentit. Tässä tapauksessa matriisielementit
pääkomponentit. Tässä tapauksessa matriisielementit  ovat normalisoituja, eivätkä pääkomponentit korreloi keskenään. Seuraa, että
ovat normalisoituja, eivätkä pääkomponentit korreloi keskenään. Seuraa, että  , Missä
, Missä  – ulottuvuuden yksikkömatriisi
– ulottuvuuden yksikkömatriisi  .
. matriiseja
matriiseja  luonnehtii alkuperäisen muuttujan välisen lineaarisen suhteen läheisyyttä
luonnehtii alkuperäisen muuttujan välisen lineaarisen suhteen läheisyyttä  ja pääkomponentti
ja pääkomponentti  , siis ottaa arvot
, siis ottaa arvot  .
. voidaan ilmaista tekijälatausten matriisin kautta
voidaan ilmaista tekijälatausten matriisin kautta  .
. -ominaisuuksia, mutta toisin kuin jälkimmäinen, normalisoinnin vuoksi nämä varianssit ovat yhtä kuin 1. Koko järjestelmän kokonaisvarianssi
-ominaisuuksia, mutta toisin kuin jälkimmäinen, normalisoinnin vuoksi nämä varianssit ovat yhtä kuin 1. Koko järjestelmän kokonaisvarianssi  - näytetilavuuden ominaisuudet
- näytetilavuuden ominaisuudet  yhtä suuri kuin näiden yksiköiden summa, ts. yhtä suuri kuin korrelaatiomatriisin jälki
yhtä suuri kuin näiden yksiköiden summa, ts. yhtä suuri kuin korrelaatiomatriisin jälki  .
. ,
, - diagonaalimatriisi, jonka päädiagonaalissa on ominaisarvot
- diagonaalimatriisi, jonka päädiagonaalissa on ominaisarvot  korrelaatiomatriisi,
korrelaatiomatriisi,  - matriisi, jonka sarakkeet ovat korrelaatiomatriisin ominaisvektoreita
- matriisi, jonka sarakkeet ovat korrelaatiomatriisin ominaisvektoreita  . Koska matriisi R on positiivinen definiitti, ts. sen johtavat minorit ovat positiivisia, sitten kaikki ominaisarvot
. Koska matriisi R on positiivinen definiitti, ts. sen johtavat minorit ovat positiivisia, sitten kaikki ominaisarvot  mille tahansa
mille tahansa  .
. löytyy ominaisyhtälön juuriksi
löytyy ominaisyhtälön juuriksi
 , joka vastaa ominaisarvoa
, joka vastaa ominaisarvoa  korrelaatiomatriisi
korrelaatiomatriisi  , määritellään yhtälön nollasta poikkeavaksi ratkaisuksi
, määritellään yhtälön nollasta poikkeavaksi ratkaisuksi
 on yhtä suuri
on yhtä suuri
 klo
klo  ).
). otosjoukon muuttujat pysyvät samoina. Sen arvot kuitenkin jaetaan uudelleen. Menettely näiden varianssien arvojen löytämiseksi on ominaisarvojen löytäminen
otosjoukon muuttujat pysyvät samoina. Sen arvot kuitenkin jaetaan uudelleen. Menettely näiden varianssien arvojen löytämiseksi on ominaisarvojen löytäminen  korrelaatiomatriisi jokaiselle
korrelaatiomatriisi jokaiselle  - merkkejä. Näiden ominaisarvojen summa
- merkkejä. Näiden ominaisarvojen summa  on yhtä suuri kuin korrelaatiomatriisin jälki, ts.
on yhtä suuri kuin korrelaatiomatriisin jälki, ts.  , eli muuttujien lukumäärä. Nämä ominaisarvot ovat ominaisuuksien varianssiarvoja
, eli muuttujien lukumäärä. Nämä ominaisarvot ovat ominaisuuksien varianssiarvoja  olosuhteissa, jos merkit olisivat toisistaan riippumattomia.
olosuhteissa, jos merkit olisivat toisistaan riippumattomia. kaikille
kaikille 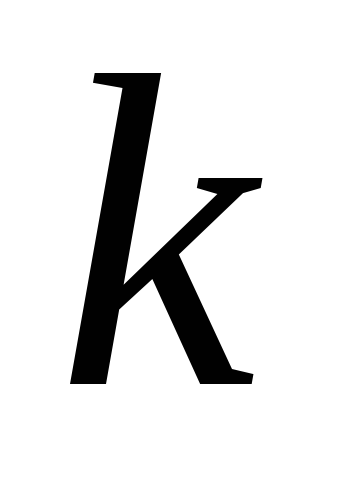 muuttujat ja
muuttujat ja  tekijät (tekijälatausmatriisi), ominaisarvot
tekijät (tekijälatausmatriisi), ominaisarvot  ja määrittää tekijöiden painot.
ja määrittää tekijöiden painot.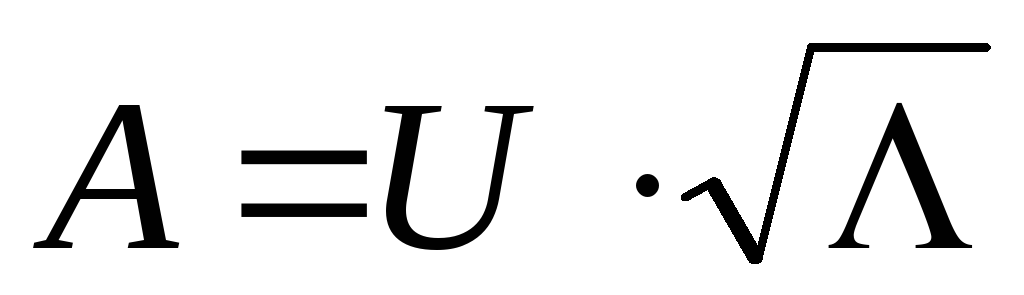 , A
, A  matriisin A sarake - miten
matriisin A sarake - miten  .
. tai
tai  kuvastaa tämän tekijän osuutta kokonaisvarianssista.
kuvastaa tämän tekijän osuutta kokonaisvarianssista. .
. - Kaiken kaikkiaan
- Kaiken kaikkiaan  -ominaisuudet on yhtä suuri kuin tietyn tekijän ominaisarvo
-ominaisuudet on yhtä suuri kuin tietyn tekijän ominaisarvo  . Sitten
. Sitten  -i:nnen muuttujan osuus prosentteina j:nnen tekijän muodostumisessa.
-i:nnen muuttujan osuus prosentteina j:nnen tekijän muodostumisessa. .
. , joka sisältää vain merkittävät kuormat. Tekijäkuormitusmatriisin avulla voit laskea kaikkien tekijöiden arvot jokaiselle alkuperäisen näytejoukon havainnosta kaavalla:
, joka sisältää vain merkittävät kuormat. Tekijäkuormitusmatriisin avulla voit laskea kaikkien tekijöiden arvot jokaiselle alkuperäisen näytejoukon havainnosta kaavalla: ,
, – t:nnen havainnon j:nnen kertoimen arvo,
– t:nnen havainnon j:nnen kertoimen arvo,  -alkuperäisen näytteen t:nnen havainnon i:nnen piirteen standardoitu arvo;
-alkuperäisen näytteen t:nnen havainnon i:nnen piirteen standardoitu arvo;  -kerroin kuormitus,
-kerroin kuormitus,  – tekijää j vastaava ominaisarvo. Nämä lasketut arvot
– tekijää j vastaava ominaisarvo. Nämä lasketut arvot  käytetään laajalti tekijäanalyysin tulosten graafiseen esittämiseen.
käytetään laajalti tekijäanalyysin tulosten graafiseen esittämiseen. .
. ,
, - muuttuva numero ja
- muuttuva numero ja  - pääkomponentin numero. Vain pääkomponenteista palautetut korrelaatiokertoimet ovat itseisarvoltaan pienempiä kuin alkuperäiset, eivätkä diagonaalilla ole 1, vaan yleisten arvot.
- pääkomponentin numero. Vain pääkomponenteista palautetut korrelaatiokertoimet ovat itseisarvoltaan pienempiä kuin alkuperäiset, eivätkä diagonaalilla ole 1, vaan yleisten arvot. - pääkomponentti määräytyy kaavan mukaan
- pääkomponentti määräytyy kaavan mukaan .
.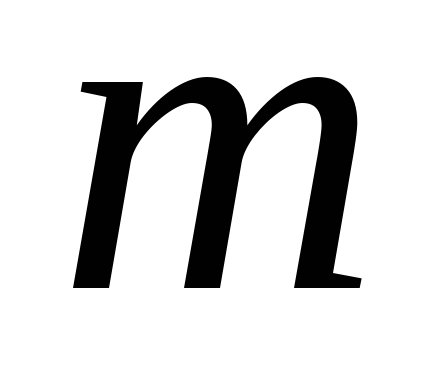 pääkomponentit määritetään lausekkeesta
pääkomponentit määritetään lausekkeesta .
.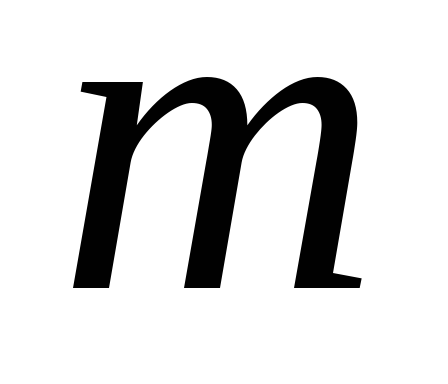 ensimmäiset pääkomponentit, joiden osuus kokonaisvarianssista on yli 60-70 %.
ensimmäiset pääkomponentit, joiden osuus kokonaisvarianssista on yli 60-70 %.
![]()


![]()













